第2.1.3章 hadoop之eclipse远程调试hadoop
本文共 3182 字,大约阅读时间需要 10 分钟。
1 eclipse配置
下载插件,将放到eclipse的plugins目录或者dropins下,重启eclipse 选择Window->Show View->Other->MapReduce Tools->Map/Reduce Locations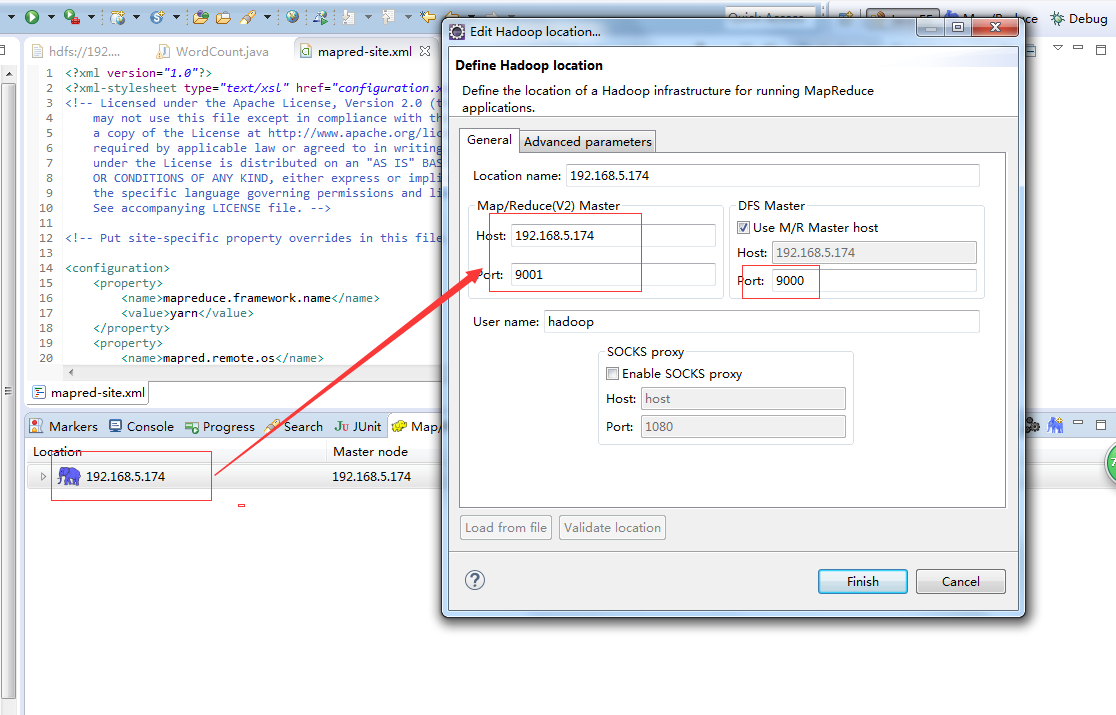 配置好后,eclipse可以连接到远程的DFS
配置好后,eclipse可以连接到远程的DFS 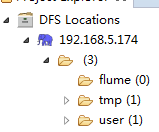 2 windows配置 选择Window->Prefrences->Hadoop Map/Reduce,配置本地的hadoop,但是本地hadoop默认即可,不需要调整。
2 windows配置 选择Window->Prefrences->Hadoop Map/Reduce,配置本地的hadoop,但是本地hadoop默认即可,不需要调整。 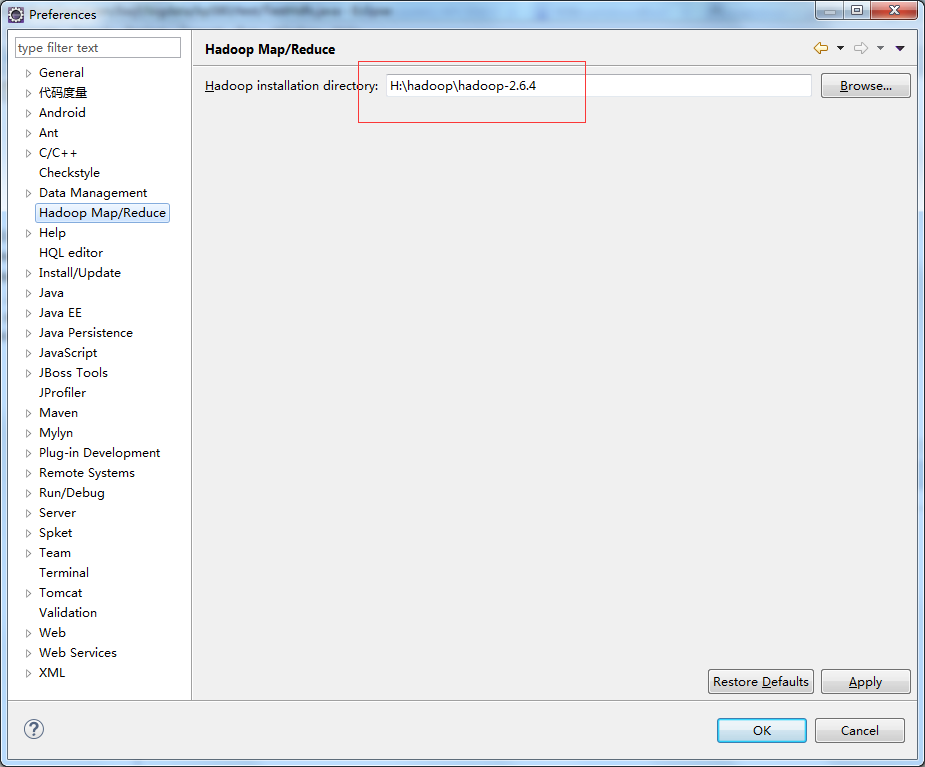 配置环境变量
配置环境变量 
将winutils.exe复制到本地hadoop的$HADOOP_HOME\bin目录
将hadoop.dll复制到%windir%\System32目录 winutils.exe和hadoop.dll的获取,您可以从csdn上下载,也可以自行在hadoop-common-project\hadoop-common\src\main\winutils编译那个.net工程 环境变量配置
 3 wordcount示例的运行 创建maven工程,不赘述,在pom.xml中引入hadoop的jar。
3 wordcount示例的运行 创建maven工程,不赘述,在pom.xml中引入hadoop的jar。 2.6.4 org.apache.hadoop hadoop-common ${ hadoop.version} org.apache.hadoop hadoop-hdfs ${ hadoop.version} org.apache.hadoop hadoop-client ${ hadoop.version}
将core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml拷贝到src/main/resources
将源码中的WordCount导入到工程中,编译Export出jar到其他的文件夹中,为方便测试命名为testWordCount.jar 然后修改工程的main代码,添加下图红色部分内容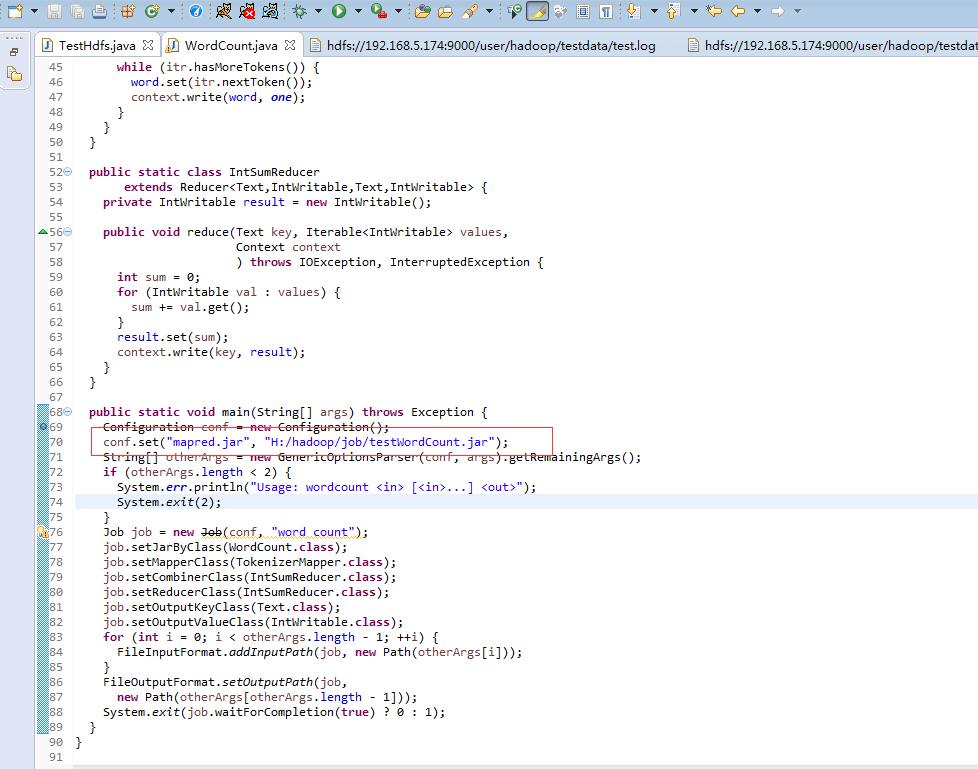 配置Run Configurations,在Arguments中添加参数 第一行hdfs://192.168.5.174:9000/user/hadoop/testdata/test.log是输入文件 第二行hdfs://192.168.5.174:9000/user/hadoop/testdata/output2是输出目录
配置Run Configurations,在Arguments中添加参数 第一行hdfs://192.168.5.174:9000/user/hadoop/testdata/test.log是输入文件 第二行hdfs://192.168.5.174:9000/user/hadoop/testdata/output2是输出目录 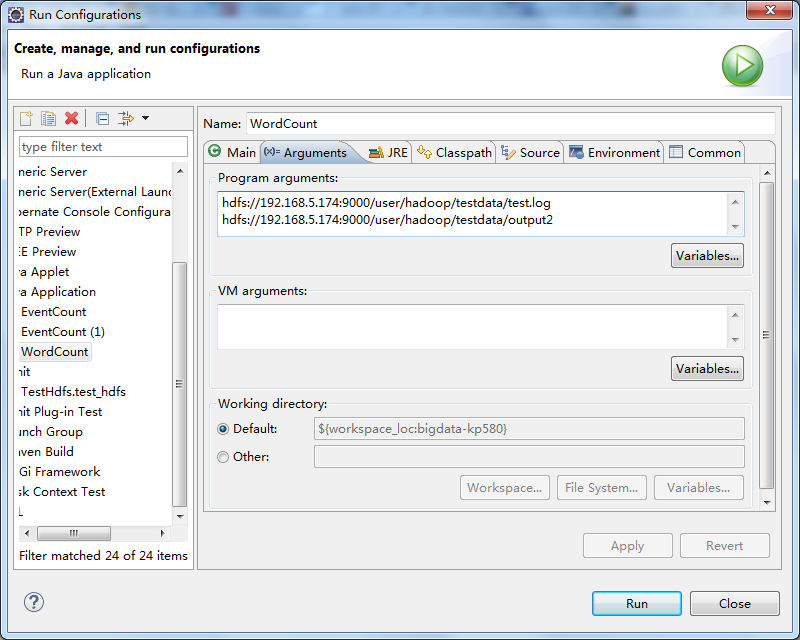 test.log的内容可通过以下代码写入
test.log的内容可通过以下代码写入 import java.io.BufferedReader;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.IOException;import java.io.InputStream;import java.io.InputStreamReader;import java.io.UnsupportedEncodingException;import java.net.URI;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FSDataOutputStream;import org.apache.hadoop.fs.FileStatus;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IOUtils;import org.junit.Test;public class TestHdfs { @Test public void test_hdfs(){ String uri = "hdfs://192.168.5.174:9000/"; Configuration config = new Configuration(); try { FileSystem fs = FileSystem.get(URI.create(uri), config); // FileStatus[] statuses = fs.listStatus(new Path("/user/hadoop/testdata")); for (FileStatus status:statuses){ System.out.println(status); } // FSDataOutputStream os = fs.create(new Path("/user/hadoop/testdata/test.log")); os.write(readFile()); os.flush(); os.close(); // InputStream is = fs.open(new Path("/user/hadoop/testdata/test.log")); IOUtils.copyBytes(is, System.out, 1024, true); } catch (IOException e) { e.printStackTrace(); } } private byte[] readFile(){ File file = new File("F:/阿里云/174/hadoop-hadoop-namenode-dashuju174.log"); StringBuffer text = new StringBuffer(); try { InputStreamReader read = new InputStreamReader(new FileInputStream(file),"UTF-8"); String lineTxt = null; BufferedReader bufferedReader = new BufferedReader(read); while((lineTxt = bufferedReader.readLine()) != null){ text.append(lineTxt).append("\n"); } read.close(); } catch (UnsupportedEncodingException | FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } return text.toString().getBytes(); }} 运行后结果
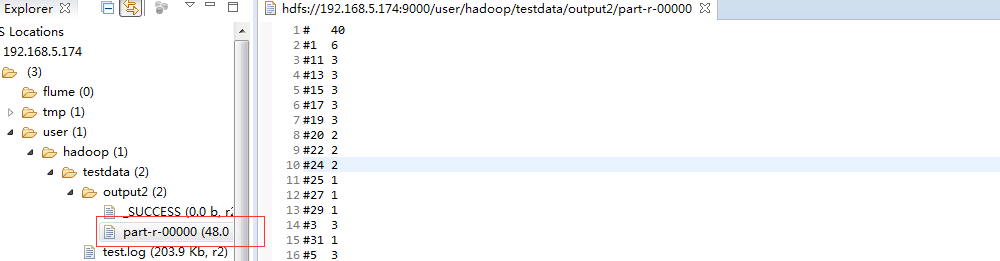
你可能感兴趣的文章
Mysql索引(4):索引语法
查看>>
mysql级联删除_Mysql笔记系列,DQL基础复习,Mysql的约束与范式
查看>>
mysql练习语句
查看>>
mysql经常使用命令
查看>>
MySQL经常使用技巧
查看>>
mysql给root开启远程访问权限,修改root密码
查看>>
mysql给账号授权相关功能 | 表、视图等
查看>>
MySQL缓存使用率超过80%的解决方法
查看>>
Mysql缓存调优的基本知识(附Demo)
查看>>
mysql编写存储过程
查看>>
mysql网站打开慢问题排查&数据库优化
查看>>
mysql网络部分代码
查看>>
mysql联合索引 where_mysql联合索引与Where子句优化浅析
查看>>
mysql联合索引的最左前缀匹配原则
查看>>
MySQL聚簇索引
查看>>
mysql自动化同步校验_Shell: 分享MySQL数据同步+主从复制自动化脚本_20190313_七侠镇莫尛貝...
查看>>
Mysql自增id理解
查看>>
mysql自增id超大问题查询
查看>>
MySQL自定义变量?学不废不收费
查看>>
MySQL自带information_schema数据库使用
查看>>